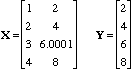In 2009 Martin Andersson published “A comparison of nine PLS1 algorithms” in Journal of Chemometrics[1]. This was a very nice piece of work and of particular interest to me as I have worked on PLS algorithms myself [2,3] and we include two algorithms (NIPALS and SIMPLS) in PLS_Toolbox and Solo. Andersson compared regression vectors calculated via nine algorithms using 16 decimal digits (aka double precision) in MATLAB to “precise” regression vectors calculated using 1000 decimal digits. He found that several algorithms, including the popular Bidiag2 algorithm (developed by Golub and Kahan [4] and adapted to PLS by Manne [5]), deviated substantially from the vectors calculated in high precision. He also found that NIPALS was among the most stable of algorithms, and while somewhat less accurate, SIMPLS was very fast.
Andersson also developed a new PLS algorithm, Direct Scores PLS (DSPLS), which was designed to be accurate and fast. I coded it up, adapted it to multivariate Y, and it is now an option in PLS_Toolbox and Solo. In the process of doing this I repeated some of Andersson’s experiments, and looked at how the regression vectors calculated by NIPALS, SIMPLS, DSPLS and Bidiag2 varied.
The figure below shows the difference between various regression vectors as a function of Latent Variable (LV) number for Melter data set, where X is 300 x 20. The plotted values are the norm of the difference divided by the norm the first regression vector. The lowest line on the plot (green with pluses) is the difference between the NIPALS and DSPLS regression vectors. These are the two methods that are in the best agreement. DSPLS and NIPALS stay within 1 part in 1012 out through the maximum number of LVs (20).

The next line up on the plot (red line and circles with blue stars) is actually two lines, the difference between SIMPLS and both NIPALS and DSPLS. These lie on top of each other because NIPALS and DSPLS are so similar to each other. SIMPLS stays within one part in 1010 through 10 LVs (maximum LVs of interest in this data) and degrades to one part in ~107.
The highest line on the plot (pink with stars) is the difference between NIPALS and Bidiag2. Note that by 9 LVs this difference has increased to 1 part in 100, which is to say that the regression vector calculated by Bidiag2 has no resemblance to the regression vector calculated by the other methods!
I programmed my version of Bidiag2 following the development in Bro and Eldén [6]. Perhaps there exist more accurate implementations of Bidiag2, but my results resemble those of Andersson quite closely. You can download my bidiag.m file, along with the code that generates this figure, check_PLS_reg_accuracy.m. This would allow you to reproduce this work in MATLAB with a copy of PLS_Toolbox (a demo would work). I’d be happy to incorporate an improved version of Bidiag in this analysis, so if you have one, send it to me.
BMW
[1] Martin Andersson, “A comparison of nine PLS1 algorithms,” J. Chemometrics, 23(10), pps 518-529, 2009.
[2] B.M. Wise and N.L. Ricker, “Identification of Finite Impulse Response Models with Continuum Regression,” J. Chemometrics, 7(1), pps 1-14, 1993.
[3] S. de Jong, B. M. Wise and N. L. Ricker, “Canonical Partial Least Squares and Continuum Power Regression,” J. Chemometrics, 15(2), pps 85-100, 2001.
[4] G.H. Golub and W. Kahan, “Calculating the singular values and pseudo-inverse of a matrix,” SIAM J. Numer. Anal., 2, pps 205-224, 1965.
[5] R. Manne, “Analysis of two Partial-Least-Squares algorithms for multivariate calibration,” Chemom. Intell. Lab. Syst., 2, pps 187–197, 1987.
[6] R. Bro and L. Eldén, “PLS Works,” J. Chemometrics, 23(1-2), pps 69-71, 2009.
 SEARCH
SEARCH

 As an example, I’ve used the clustering function on a Landsat image of the Mississippi River. This 512 x 512 image has 7 channels. Working from the purely point-and-click Analysis interface on my 4 year old MacBook Pro laptop, this image can be clustered into 3 groups in 6.8 seconds. The result is shown at the far left. Clustering into 6 groups takes just a bit longer, 13.8 seconds. Results for the 6 cluster analysis are shown at the immediate left. This is actually a pretty good rendering of the different surface types in the image.
As an example, I’ve used the clustering function on a Landsat image of the Mississippi River. This 512 x 512 image has 7 channels. Working from the purely point-and-click Analysis interface on my 4 year old MacBook Pro laptop, this image can be clustered into 3 groups in 6.8 seconds. The result is shown at the far left. Clustering into 6 groups takes just a bit longer, 13.8 seconds. Results for the 6 cluster analysis are shown at the immediate left. This is actually a pretty good rendering of the different surface types in the image.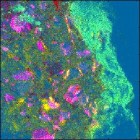
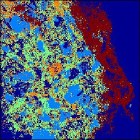 As another example, I’ve used the image clustering function on the SIMS image of a drug bead. This image is 256 x 256 and has 93 channels. For reference, the (contrast enhanced) PCA score image is shown at the far left. The drug bead coating is the bright green strip to the right of the image, while the active ingredient is hot pink. The same data clustered into 5 groups is shown to the immediate right. Computation time was 14.7 seconds. The same features are visible in the cluster image as the PCA, although the colors are swapped: the coating is dark brown and the active is bright blue.
As another example, I’ve used the image clustering function on the SIMS image of a drug bead. This image is 256 x 256 and has 93 channels. For reference, the (contrast enhanced) PCA score image is shown at the far left. The drug bead coating is the bright green strip to the right of the image, while the active ingredient is hot pink. The same data clustered into 5 groups is shown to the immediate right. Computation time was 14.7 seconds. The same features are visible in the cluster image as the PCA, although the colors are swapped: the coating is dark brown and the active is bright blue.