 SEARCH
SEARCHRegression Vectors and the Limits of ChatGPT
Sep 26, 2025
A few weeks back Rasmus Bro sent us an email about a little experiment he performed. His colleagues were discussing the utility of having students write reports, wondering if the reports could be replaced with output from ChatGPT. So he submitted the two figures below and prompted it with:
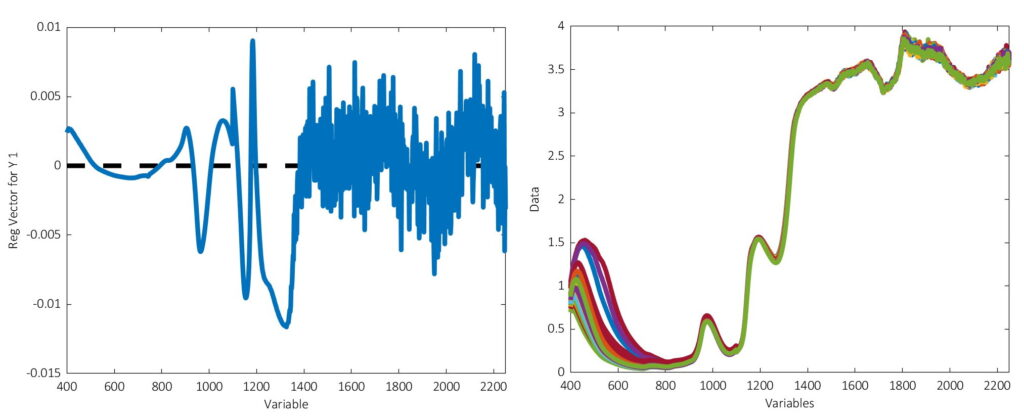
I am writing a report for a university course on advanced chemometrics. I have built a PLS prediction model predicting Real Extract in beer (40 samples) from the attached VISNIR spectra (spectra.jpg) and yielding the regression vector in regressionvector.jpg. I am asked to critically describe what I learn from the regression vector
ChatGPT produced an excellent report, the full text of which you can find here. The only problem? The very first thing out of its virtual mouth was wrong. The report stated that “Positive [regression] coefficients mean absorbance at that wavelength is positively correlated with Real Extract” and that “Negative coefficients mean absorbance at that wavelength is negatively correlated with Real Extract.”
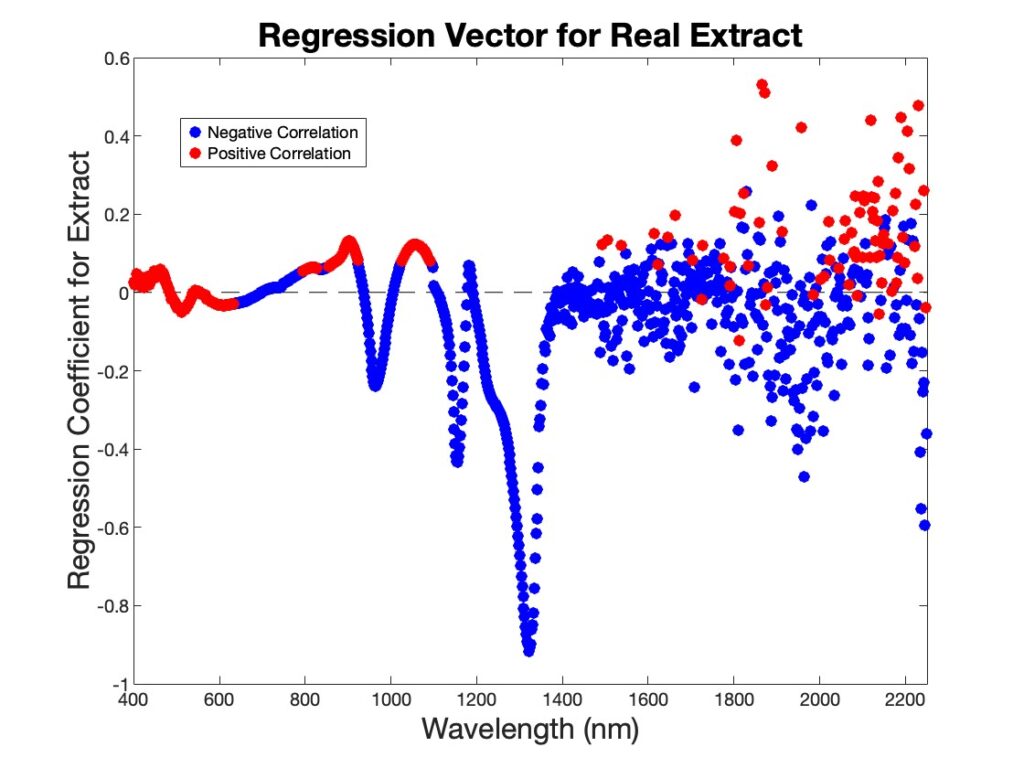
This not correct in general, and not correct in this instance either, although it is closer in this case than usual. The regression vector for this example is shown below, with coefficients colored blue for negative correlation between Real Extract and absorbance at that wavelength and red for positive correlation. You can see that the negative coefficients tend to be blue, and the positive ones tend to be red, but there are plenty of instances of the reverse of this.
In general, the correlation between absorbance at a wavelength and the chemical analyte concentration or property of interest can be positive, negative or zero. It all depends on the degree of overlap of the components and whether the interfering species are positively or negatively correlated with that concentration. And all of that is actually independent of the regression vector. The regression vector is the part of the analyte signal that is orthogonal to the interferents. This doesn’t change regardless of how these interferents are correlated with analyte of interest (except in the extreme case of them being perfectly correlated or anti-correlated in which case orthogonality can’t be determined).
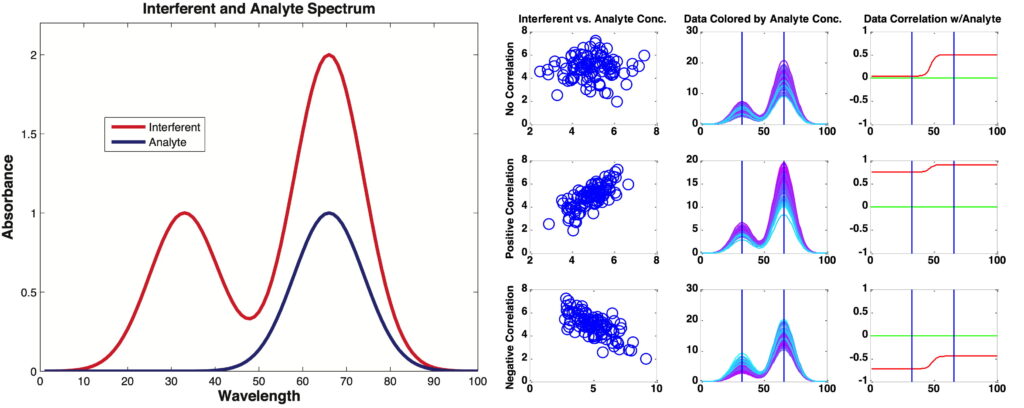
We teach this in our Variable Selection course, and it demonstrates one of the reasons that variable selection is so difficult. You can’t just pick variables that are correlated with the analyte of interest. The figure below shows on the left the spectra of a system where the analyte of interest is entirely overlapped by an interferent, (which is not at all uncommon in NIR!). On the right it is shown that, depending on the degree of correlation between the interferent and the analyte, the correlation between wavelengths and analyte can be positive, negative or zero. More complex systems can produce even more unintuitive behavior, such as instances where the variables most correlated to the analyte of interest have no signal from it all.
All this demonstrates the problem with ChatGPT: it is no smarter than all the text it has scraped up. (Maybe it will get smarter after reading this.) Common misconceptions, like this one, will likely be regurgitated. That means that EVERYTHING it produces is suspect and therefore requires that it be verified before being used for anything important. This is even scarier when you realize that it doesn’t know when it is training on misinformation that it produced, thus reinforcing and perpetuating misconceptions. Getting back to original human-produced sources is getting increasingly difficult.
Bottom line: if you are going to use ChatGPT or its brethren allow yourself some time to verify its output. When you do, you might find it isn’t saving you as much time as you think.
BMW